![]()
개요
자바의 I/O의 스트림이 아닌 데이터 컬렉션과 유사한 것으로, 자바8에서 새롭게 등장한 함수형 프로그래밍의 스트림을 학습해본다. 스트림이라는 표현은 주로 어떤 데이터의 흐름을 말한다. 이번 자바 8에서 새롭게 나온기 전에도 자바에서 사용하던 용어로 java.io 패키지에 있는 I/O 프로그래밍에 활용되는 클래스명에 Stream이라는 단어를 사용하고 있다. 이번에 학습할 스트림은 주로 컬렉션 프래임워크나 이와 유사한 형태의 데이터를 처리하는 자바8에서 새롭게 제안한 API 이다.
스트림 인터페이스
자바 8의 스트림은 java.util.stream 패키지에 정의되어 있다. 스트림은 람다 표현식이나 메서드 참조를 통해 구체적인 구현체를 전달 받아 동작하기 때문에 함수형 인터페이스와 관련이 있다. 스트림에서 가장 기본이 되는 인터페이스는 BaseStream이며 제네릭 타입으로 <T, S extends BaseStream<T, S»가 인터페이스에 추가적으로 정의되어 있다.
T: 스트림에서 처리할 데이터의 타입을 의미한다.
S: BaseStream을 구현한 스트림 구현체를 의미한다. 이 구현체에는 BaseStream 인터페이스 외에도 스트림을 자동으로 종료하기 위한 AutoCloseable 인터페이스도 구현되어 있어야 한다.
BaseStream 인터페이스는 스트림 API의 최상위에 있으며, 스트림 객체를 병렬 혹은 순차 방식으로 생성하고 최종적으로 종료하기 위한 명세를 제공한다. 가장 기본이 되는 인터페이스지만 실질적으로 BaseStream 상속한 Stream 인터페이스를 주로 사용한다.

스트림 내부적으로 오토 박싱과 언박싱이 빈번하게 발생하고, 이는 처리 시간의 급격한 증가를 가져오기 때문에 스트림 API에서는 기본형으로 많이 사용하는 int, long, double 을 위한 별도의 인터페이스를 제공하고 있다.
- DoubleStream: Double형 데이터 처리에 특화되어 있다.
- IntStream: int형 데이터 처리에 특화되어 있다.
- LongStream: long형 데이터 처리에 특화되어 있다.
기본형 스트림 인터페이스에는 기본형 데이터를 처리하기 위한 메서드를 추가 되어 있다.
- sum: 스트림에 포함된 데이터의 합계를 리턴한다.
- max: 스트림에 포함된 데이터의 최댓값을 리턴한다.
- min: 스트림에 포함된 데이터의 최솟값을 리턴한다.
스트림 객체
Collection 인터페이스에 Stream
public class FirstStreamExample {
public static void main(String[] args) {
List<Stream> fistList = new ArrayList<>();
firstList.add("1");
firstList.add("2");
firstList.add("3");
firstList.add("4");
firstList.add("5");
System.out.println("First List : " + firstList);
// 스트림 객체를 생성한다.
Stream<String> firstStream = firstList.stream();
// 스트림 객체의 크기를 조회한다. (최종 연산)
System.out.println("Stream 항목 개수 : " + firstStream.count());
// 스트림에서 앞에서 5개의 데이터를 한정해서 새로운 스트림 객체를 생성한다.
// (중간 연산)
Stream<String> listedStream = firstStream.limit(5);
listedStream.forEach(System.out::println);
}
}
output)
First List : [1,2,3,4,5]
Stream 항목 개수 : 10
IllegalStateException: stream has already been operated upon or closed // 예외 발생
stream을 통해 개수를 조회하였고, 추가로 limit을 앞에서 5개의 데이터를 스트림을 가져오기 위해 limit 메서드를 호출하였지만 IllegalStateException이 발생하였다. 이 예외를 통해 스트림의 특징을 알 수 있는데 그 내용을 정리하면 다음과 같다.
- 스트림은 한번 사용하고 나면 다시 사용할 수 없다. 데이터의 흐름이며 한번 흘러간 데이터는 다시 돌아오지 않는다.
- Stream 인터페이스의 메서드 중 void를 리턴하는 메서드를 호출하면 전체 스트림 데이터를 처리하기 때문에 데이터를 모두 소모하고 종료된다.
스트림 데이터를 다 소모하게 만드는 count 같은 메서드를 특별히 최종 연산이라고 한다.
스트림 빌더
컬렉션을 통해 스트림 객체를 생성하는 시점은 이미 컬렉션 프레임워크를 이용해서 객체 내부에 모든 데이터를 추가한 이후가 대부분이다. 그러므로 데이터를 소모하는역할만 하고 데이터를 생성하는 역할을 수행하지 않는다. 스트림에서는 생성된 데이터를 처리하는 것에서 끝나지 않고 데이터를 직접 생성하기 위한 기능도 제공하는데 그것이 바로 스트림 빌더이다.
- 스트림 API 자체적으로 스트림 구성 항목을 생성할 수 있다.
- 스트림 객체를 생성하기 위해 List 등의 컬렉션 프레임워크를 이용해서 임시로 데이터를 만드는 작업을 하지 않아도 된다.

스트림 빌더 역시 스트림 객체와 마찬가지로 한 번 사용하고 나면 재사용할 수 없다는 점을 잊지 말아야 한다.
Stream stream1 = builder.build();
stream1.forEach(System.out::println);
Stream stream2 = builder.build(); // IllegalStateException 발생
stream2.forEach(System.out::println);
Accept 메서드 vs add 메서드 차이
accept 메서드를 이용한 것으로 리턴 타입이 void이다. 즉, 생성한 스트림 빌더 객체에 데이터를 계속 누적해서 쌓을 수 있다. add 메서드는 리턴 타입이 스트림 빌더이다. add 메서드가 리턴하는 스트림 빌더 객체는 새롭게 생성되는 객체가 아니라 자기 자신이다. add 또는 accept를 이용하든 성능이나 메모리 처리 등에서 큰 차이가 없다.
스트림 연산 이해
파이프라인을 이용해서 명령어를 조합하면 한 줄의 코드로 강력한 결과를 확인할 수있다. 이렇게 셸 스크립트에서 명령어와 파이프라인의 조합을 이용하면 무궁무진한 기능 조합을 만들어낼 수 있다. 스트림 API 기반의 연산 작업을 선호하는 이유는 파이프라인과 유사한 개념으로 기능을 조합할 수 있기 때문이다.
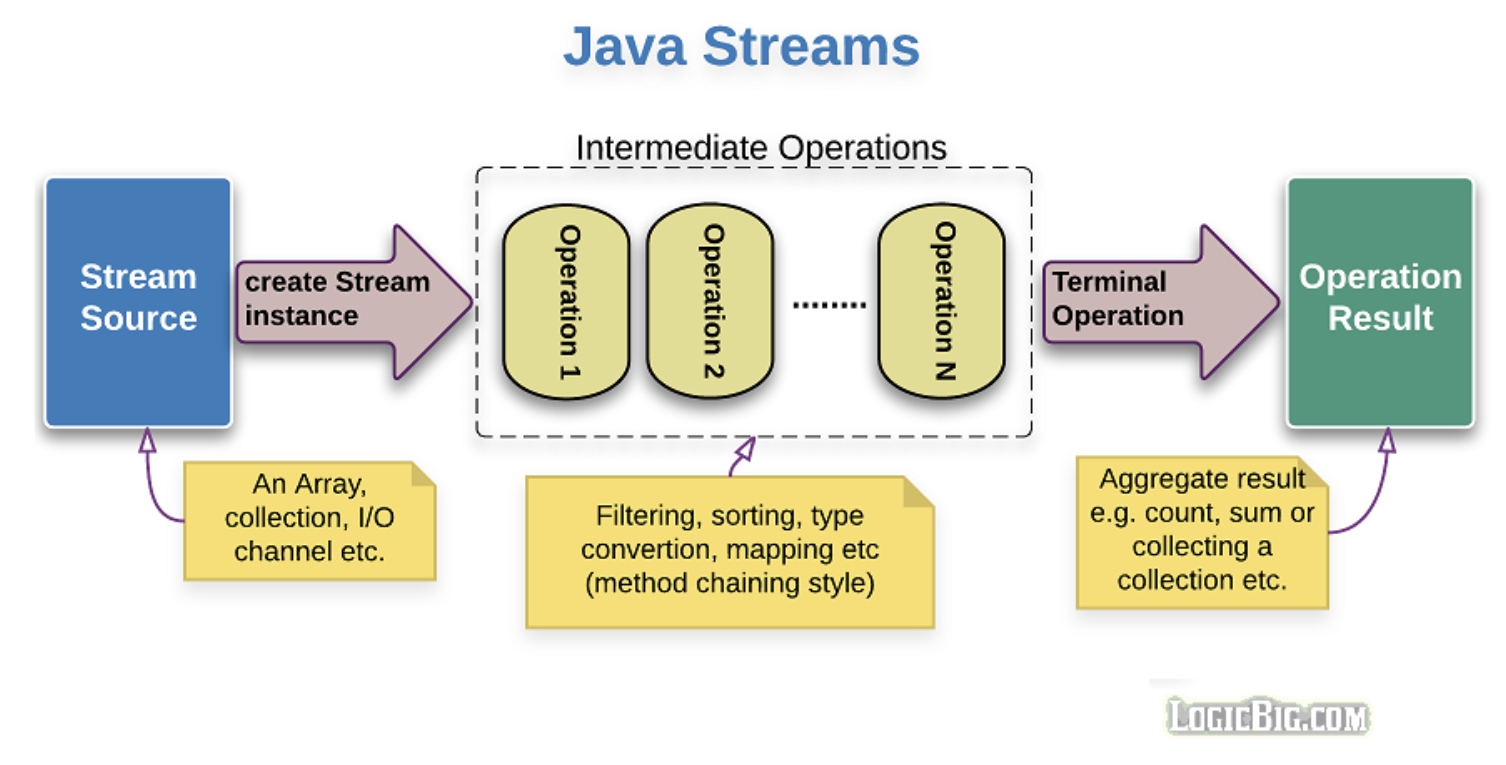
스트림 객체가 생성되는 단계: 주로 Collection이나 Array 등에서 stream 메서드를 호출해서 생성되며, 스트림의 저수준 API를 이용해서 직접 생성하는 경우도 있다.
중간 연산 단계: 스트림의 데이터들을 필터링하고, 정렬하고, 변환하는 단계를 거친다. 각 단계의 리턴 값 역시 새로운 스트림 객체이다.
최종 연산 단계: 스트림 객체의 데이터를 전부 소모하고 스트림을 종료한다.

중간 연산)
public static <T> Predicate<T> distinctByKey(Function<? super T, ?> key) {
Map<Object, Boolean> seen = new ConcurrentHashMap<>();
return t -> seen.putIfAbsent(key.apply(t), Boolean.TRUE) == null;
}
personList.stream()
.filter(distinctByKey(b -> (b.getName() + b.getAge())))
.forEach(System.out::println);
최종 연산)
public class StreamCollectExample {
public static void main(String[] args) {
List<person> personList = new ArrayList<>();
personList.add(new Person("장윤기", 45));
personList.add(new Person("장해라", 18));
List<Person> sortedList = personList.stream().sorted().collect(Collectos.toList());
}
}
데이터 검색
필터링과 검색은 차이가 있다. 필터링은 고정된 유형으로 데이터의 참과 거짓을 판별해서 원하는 데이터 집합을 생성하는 것을 의미한다. 하지만 데이터 검색한다는 의미는 특정한 패턴에 맞는 데이터를 조회하는 것이다. 그리고 하나의 패턴이 아니라 여러 개의 패턴을 조합해서 자기가 원하는 데이터를 정확히 검색할 수도 있다.
- allMatch: 주어진 람다 표현식 기준으로 스트림의 데이터가 하나라도 일치하는지 확인한다.
- anyMatch: 주어진 람다 표현식 기준으로 스트림의 데이터가 하나라도 일치하는지 확인한다.
- noneMatch: 주어진 람다 표현식 기준으로 스트림의 데이터가 모두 일치하지 않는지 확인한다.
Predicate 인터페이스로 구현한 람다 표현식)
boolean answer1 = numberList.stream().allMatch(number -> number < 10);
System.out.println("10 보다 모두 작은가요? : " + answer1);
boolean answer2 = numberList.stream().anyMatch(number -> number % 3 == 0);
System.out.println("3의 배수가 있나요? : " + answer2);
boolean answer3 = numberList.stream().noneMatch(number -> number %2 == 0);
System.out.println("양수가 없나요? : " + answer3);
match는 최종 연산이기 때문에 find 계열 메서드로 중간연산 처리할 수있다.
- findFirst: 스트림이 가지고 있는 데이터 중 가장 첫 번째 값을 리턴한다.
- findAny: 스트림이 가지고 있는 데이터 중 임의의 값을 리턴한다.
Optional<Integer> results = list.stream().parallel().filter(num -> num < 4).findAny();
리듀스 연산
reduce 메서드를 이용하면 스트림의 병렬 처리 기법을 활용할 수도 있다. 특히 처리해야 하는 데이터가 많을 때 병렬 스트림으로 리듀스 연산을 하면 성능을 크게 높일 수 있다.
- 메서드의 첫 번째 인수는 초깃값을 의미한다.
- 메서드의 두 번째 인수는 BinaryOperator이다. 이 인터페이스는 두 개의 인수를 받아서 하나의 값으로 리턴하는 함수형 인터페이스이다. (첫번째 인수는 이전값, 두번째는 새로운 인수)
int sum = intList.parallelStream().reduce(0, Integer::sum);
System.out.println("sum : " + sum);
정리
- 스트림 API에서 가장 핵심이 되는 것은 Stream 인터페이스이다.
- 스트림 API는 인터페이스의 실제 구현체를 제공하지 않으며 컬렉션 프레임워크, 배열이나 관련된 프레임워크에서 해당 데이터에 맞게 구현해 놓았다.
- 데이터를 정렬/필터링/맵핑하는 등의 작업을 중간연산, 컬렉션으로 변환/출력하는 등 최종 소모하는 작업을 최종 연산이라고 한다.
- 다중 배열 형태의 데이터를 처리하기 위해 데이터의 평면화(flatMap) 기능을 제공한다.
- 리듀스 연상을 이용하면 데이터의 합계, 최댓값, 최솟값 등을 구할 수 있으며 람다 표현식을 이용해서 데이터 간의 연결 고리도 만들어 낼 수 있다.